Enriching Audio with Whisper
- UUID: e07ff0af-dfb2-4a22-97de-279cb63d7c5d
Transcripting audio speech is a very common task, and simple on the surface but hard inside the black box. Whisper gets well-known more or less together with the marketing of ChatGPT. Putting all the fancy marketing terms aside, I think whisper should be something worth writing an article on my JH-Articles website.
Whisper represents something best in the world. It is a free open source software project which enables almost everybody on a basic task - transcripting audio. There is also another instance worth mentioning, which is Tesseract - also FOSS, also on a basic task -
recognizing optical character on image, which has been helping me much since I knew it in 2020.
What is Whisper?
https://github.com/openai/whisper
Robust Speech Recognition via Large-Scale Weak Supervision
Whisper is a general-purpose speech recognition model.
It is trained on a large dataset of diverse audio and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification.
Official introduction feels too much for me (or possibly you), especially when I am not sure about the meaning of certain field terms. In plain English, it is a tool which can help to transcribe audio files to texts, among many of its capabilities.
How to use Whisper?
The free way is to just use Whisper, while the easiest or at least easier way is to use Whisper by using a curated application which embeds Whisper.
Becase I am more writing about the best thing in the world, the free open source software, let me stick with the FOSS by avoiding proprietary applications which embed Whisper.
According to the GitHub page at the above given link, Whisper is implemented with almost 100% Python as the languages and it is installable via Python's package manager - pip with a prerequisite of ffmpeg which is also FOSS. (Worth mentioning, FOSS projects also differ in terms of licenses which define the free use senarios.)
If you are lucky (without unexpected issues, which are unfortunitely not always the case), installation can be as easy as the following two lines if on macOS. (Of course, the basic environment, like macOS, HomeBrew, and proper Python are already installed on your metal.)
pip install -U openai-whisper
brew install ffmpeg
After installation, the use is also as easy as one-liner command lines. Such as what are given on the GitHub page.
# if you will transcribe speech in audio files, using the medium model:
whisper audio.flac audio.mp3 audio.wav --model medium
# if to transcribe an audio file containing non-English speech, you can specify the language using the --language option:
whisper japanese.wav --language Japanese
# Adding --task translate will translate the speech into English:
whisper japanese.wav --language Japanese --task translate
And for a bit more advanced uses, as Whisper is 100% Python in certain aspect and using Python wouldn't be considered as unusually nowadays, as simpel as just the following several lines of Python code can do the task.
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
You can achieve something like what I have done today as shown in the following image: An Apple News Today podcast audio was transciped into text for me to consume the content in a way where there is not only just audio but also text which is not available by default.
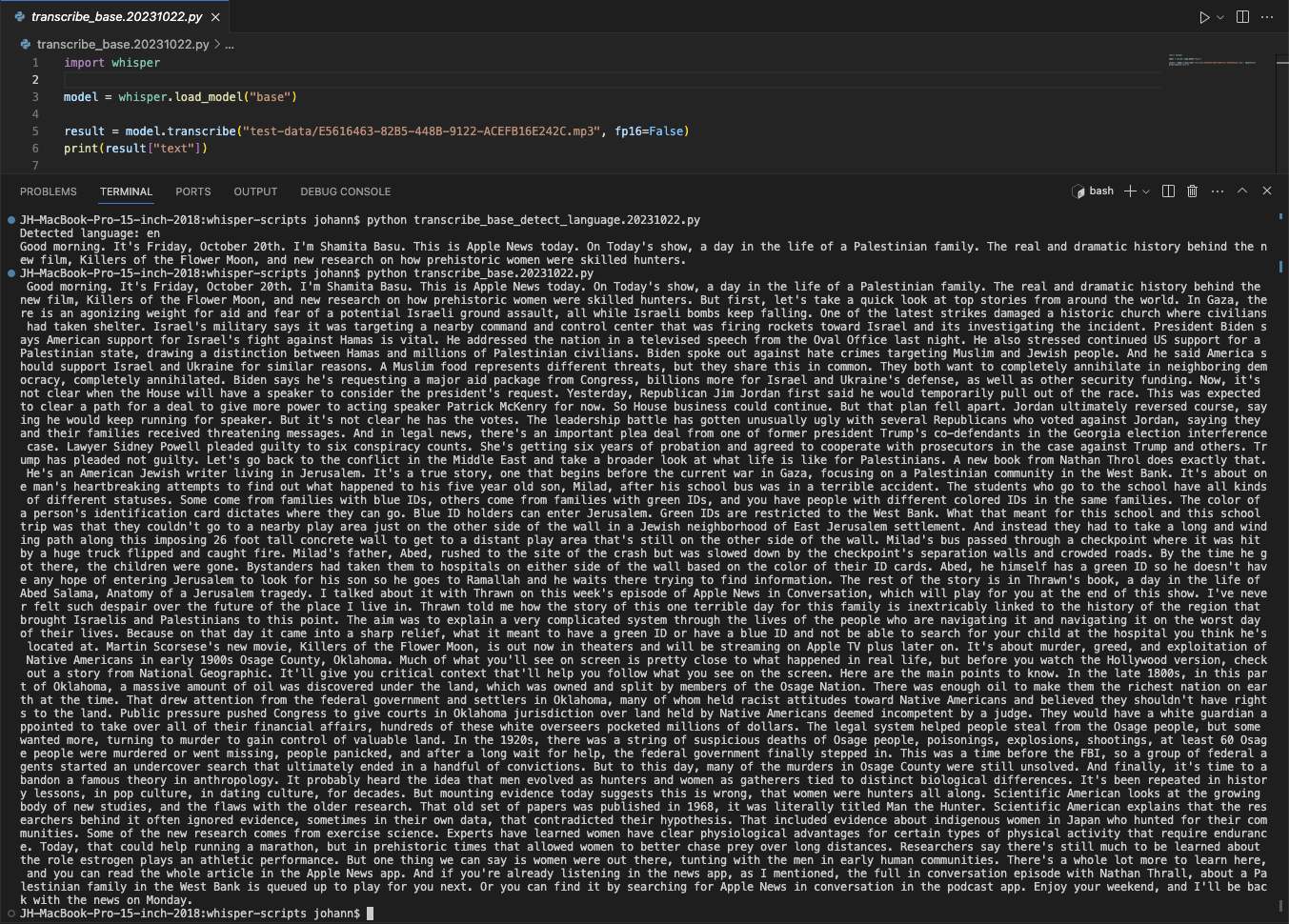
What's more? I can also use the podcast toghether with the transcript text to learn English pronounciation!
Remark
I thought to make the title something like "Enrich Your Audio with Whisper" to act like I am teaching or like "Enrich Your Podcasts with Whisper" which puts the article closer to the trend. But I think, it is better to let this article less about me or you, and not so purposefully attaching it to the trend therefore as a side effect narrow-scoping it or timestamping it.
The website has been silent for sometime now, with a change of my own personal status in terms of time distribution, I hope I can make the website more alive than in the past 2 years.
* cached version, generated at 2024-01-11 10:55:45 UTC.
Subscribe by RSS