Making Better Dictionaries for Language Learning
- UUID: 4b1583f8-5751-49b9-8131-cb712121c093
- Timestamps
- 20231120, started this article
About Copyright
Copyright is a very good and necessary design which helps to promote investment on innovation and efforts. If there is no copyright, people who make things which can be easily copied but require a lot of investment to invent (to make the first copy) will very much likely decide not to invent at first place.
However, copyright also decreases the likelyhood of further development when the owner of the copyright-protected contents are not willing to make an improvement. The balance is really not a simple topic to address.
As a foreign language learner, I value very much of a proper dictionary. For my German learning, I really like the "PONS Basiswörterbuch Deutsch als Fremdsprache", for its proper amount of vocabulary as well as not too long or not too short definitions. However, it has no digital version which is easy to use. Apparently, it is copyright protected commercial product. Looking up words in a paper dictionary book is not usually convenient.
Is there a way for me to take better use of the "PONS Basiswörterbuch Deutsch als Fremdsprache"? In fact, I have been trying to make my own digital version of this dictionary for several years now. It took already so many years, because it is not really an easy task.
To address the copyright issue, my solution is to just make my own digital version. I think it should be considered as safe if I don't distribute the digital version I have made. I purchased the paper version, and I make the digital version of the paper version just for my own convinient use of the paper version. In fact, I have purchase several paper books of this "PONS Basiswörterbuch Deutsch als Fremdsprache" - the German only version and also the definitions in both German and Chinese version. I got my photocopied PDF digital versions which serve as the starting point of making better dictionaries for language learning.
Making my "PONS Basiswörterbuch Deutsch als Fremdsprache"
Photocopied PDF files are not really more convinient than the paper books except for the part of portability or reproduction. For dictionaries, the index or the ease of headword definition retrieving is essential. Photocopied PDF files are commonly not so easy to search from. Even it there is OCR layer added by the scanner. There could still be the precision issue. Be it to many occurrences of a certain word which is not as headword or the headword is not accurately OCR-ed.
What I have done in the past several years? Well it is in the past and I forgot quit some details. But there remain still the stems. Starting from photocopied PDF files, I have done the following steps.
- Do an OCR with
Tesseract - Use proper Regex to get the headwords and separate the whole OCR-ed text
- therefore, I got a wordlist
- and the rough defintion parts for each words in the wordlist
- However, the quality of the defintion OCR-ed text is not in very good quality
- Which takes a lot of time for manual correction
- I am afraid of errors because of the OCR, so I also started my long process of making word by word screenshots
- therefore, I got a directory of screenshots of individual words
It is okay for me to do the screenshots for individual words, although it indeed has taken a lot of my time. But my time has not been purely spent on taking the screenshots. I have been reading the dictionary. It took several years also because I broke the dictionary reading process in between. (Because of the focus shift.) Now, I am back again on the dictionary reading. It is also the reason why I started this article.
Headword wordlist and screenshots of individual words are not the things I have.
The screenshots are not really good enough directly after taken by hands. So I have also write quit some Python scripts to post-process the images. Like shown in the following screenshot of my VS Code.
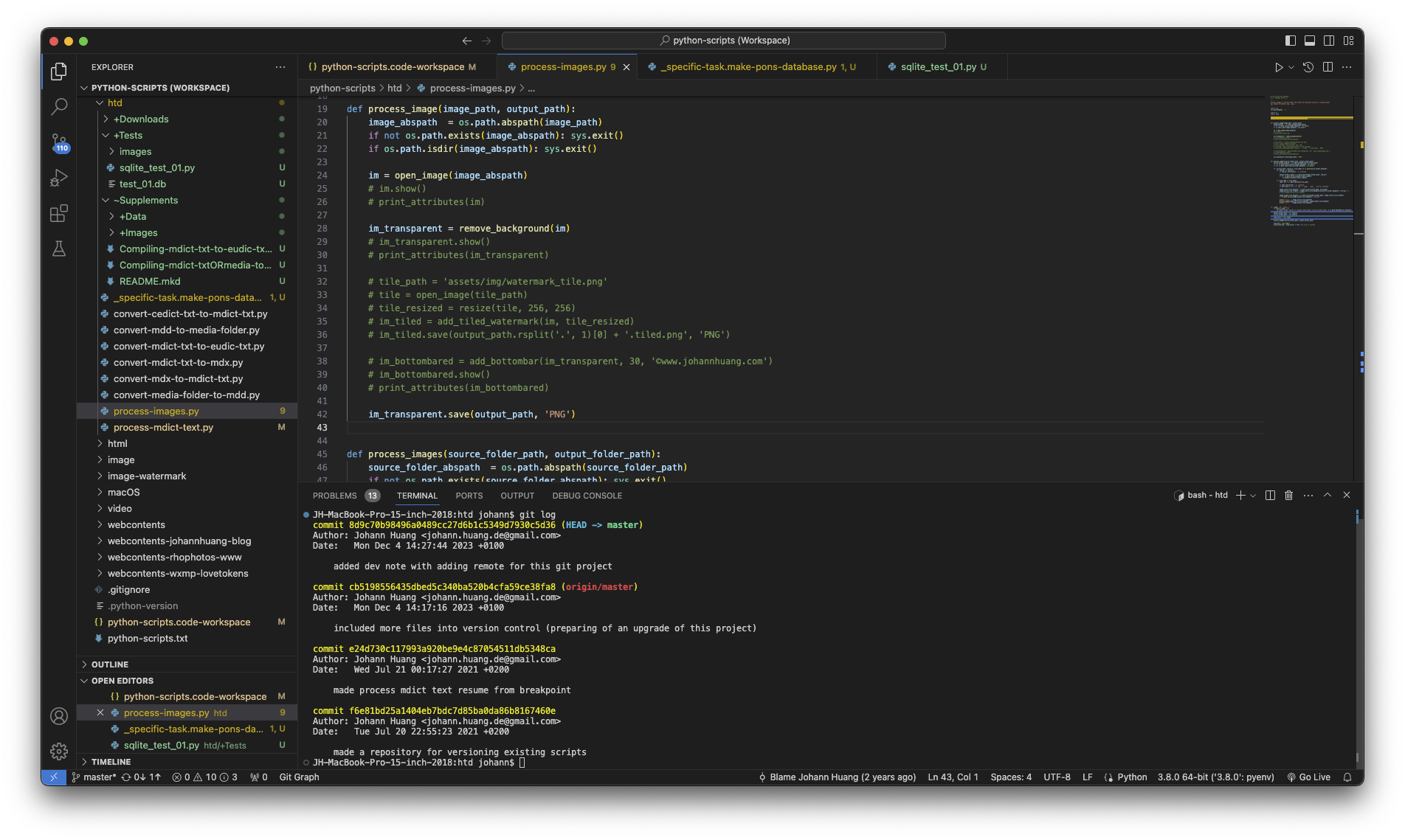
Like shown in the image, I have wrote the method to remove background from the word screenshots.
And with more post processing, the final result is like the following.

The above image is taken from GoldenDict, which is an open source dictionary data lookup program. It supports quite a few dictionary data format. With the transparent individual word screenshots and the wordlist, there are several data formats that can be used to make the lookup in GoldenDict possible.
What's more?
In fact, individual word screenshots is already much much better than the paper dictionary. However, GoldenDict is only available on major desktop OS's.
Therefore, again, build my own! Then it becomes a topic I am recently very much into - selection best tech stack for cross-platform application development.
Making Cross-platform Dictionary Application
Data is usually an essential part of an application, especially for dictionary applications. But fortunitely, there is a lightweight database which works on all major OS's - be it desktop or mobile - which is SQLite.
So before making the dictionary application, the first step would be make the database.
Well, as a matter of fact, I haven't done with the screenshots of individual words, as I haven't done with the dictionary book reading. Like that I haven't done with the dictionary reading, I also haven't done with my Python script for making the database. But the essential idea was already there, which could be interesting for people who may also have the same idea to make own dictionaries for langauge learning. Therefore, to conclude my day, I am posting my Python script here, for the reference of others or myself coming back in the future.
import sys
sys.path.append('..')
import os
import sqlite3
from PIL import Image
from _.image import convert_to_base64_string
def process_image(image_path):
image_abspath = os.path.abspath(image_path)
if not os.path.exists(image_abspath) or os.path.isdir(image_abspath):
print('!!!!!! invalid path: ', image_path)
print('>>>>>> start to process image file: ', image_abspath)
im = Image.open(image_abspath)
# im.show()
# print_attributes(im)
base64_string = convert_to_base64_string(im)
# save_to_file(image_path + '.base64.txt', 'data:image/png;base64,' + base64_string)
print('<<<<<< finished processing image file: ', image_abspath)
return base64_string
# IDEA: use MariaDB type to define column types: INT, DOUBLE, TEXT
# NOTE: it is necessary to make con.commit() before con.close(), otherwise, the data will not be written in database
# NOTE: about con.commit():
# REF: https://stackoverflow.com/questions/36243538/python-sqlite3-how-often-do-i-have-to-commit
# This is what everybody thinks of at first sight: When a change to the database is committed, it becomes visible for other connections.
# Unless it is committed, it remains visible only locally for the connection to which the change was done.
# Because of the limited concurrency features of sqlite, the database can only be read while a transaction is open.
def make_database():
try:
con = sqlite3.connect('pons.dictionaries.db')
# NOTE: Besides PONS Basiswörterbuch Deutsch als Fremdsprache
# There is also PONS Großwörterbuch Deutsch als Fremdsprache
# as well as PONS Basiswörterbuch Englisch, PONS Basiswörterbuch Italienisch, ...
sql_query = "SELECT 1 FROM sqlite_master WHERE type = 'table' AND name = 'pons_deu_basis'"
if not con.execute(sql_query).fetchone():
# NOTE: MariaDB style
# sql_create_table = "CREATE TABLE pons_deu_basis (id INT AUTO_INCREMENT, headword TEXT, deu_image_png_base64 TEXT, deuzho_image_png_base64 TEXT, PRIMARY KEY (id));"
sql_create_table = "CREATE TABLE pons_deu_basis (id INTEGER PRIMARY KEY AUTOINCREMENT, headword TEXT, deu_image_png_base64 TEXT, deuzho_image_png_base64 TEXT);"
con.execute(sql_create_table)
con.commit()
deu_png_images_path = '.../PONS Basiswörterbuch Deutsch als Fremdsprache/Screenshots-Transparent'
deuzho_png_images_path = '.../外研社德汉双解德语学习词典/Screenshots-Transparent'
print(deu_png_images_path, deuzho_png_images_path)
# TODO:
# 1. make two lists of image files in both directories: (headword, relative_path)
# 2. merge the two lists into one list: (headword, deu_rel_path, deuzho_rel_path) - a database join
# 3. sort the above list
# 4. optional: compare with the list from Excel to identify possible errors
# headword = 'A'
# if not con.execute("SELECT 1 FROM pons_deu_basis WHERE headword = ?", (headword,)).fetchone():
# image_path = f'images/{headword}.png'
# deu_image_png_base64 = None
# deuzho_image_png_base64 = process_image(image_path)
# con.execute("INSERT INTO pons_deu_basis(headword, deu_image_png_base64, deuzho_image_png_base64) VALUES(?, ?, ?)", (headword, deu_image_png_base64, deuzho_image_png_base64))
# con.commit()
# print('Inserted', headword)
# else:
# # For deu_image_png_base64
# if not con.execute("SELECT 1 FROM pons_deu_basis WHERE headword = ? AND deu_image_png_base64 IS NOT NULL;", (headword,)).fetchone():
# deu_image_png_base64 = 'fake_deu_image_png_base64'
# con.execute("UPDATE pons_deu_basis SET deu_image_png_base64 = ? WHERE headword = ?", (deu_image_png_base64, headword))
# con.commit()
# print('Updated', headword, deu_image_png_base64)
# # For deuzho_image_png_base64
# if not con.execute("SELECT 1 FROM pons_deu_basis WHERE headword = ? AND deuzho_image_png_base64 IS NOT NULL;", (headword,)).fetchone():
# deuzho_image_png_base64 = 'fake_deuzho_image_png_base64'
# con.execute("UPDATE pons_deu_basis SET deuzho_image_png_base64 = ? WHERE headword = ?", (deuzho_image_png_base64, headword))
# con.commit()
# print('Updated', headword, deuzho_image_png_base64)
# NOTE: when there is pons_deu_basis, the results for the following query will be [('pons_deu_basis',), ('sqlite_sequence',)]
# sql_query = "SELECT name FROM sqlite_master WHERE type='table'"
# results = con.execute(sql_query).fetchall()
# NOTE: Inspection: check all table names
# i = 0
# for row in con.execute("SELECT name FROM sqlite_master WHERE type='table'"):
# i += 1
# print(i, row)
# NOTE: Inspection: check all records
# print('Read pons_deu_basis')
# for row in con.execute("SELECT * FROM pons_deu_basis"):
# print(row)
except sqlite3.Error as error:
print(error)
finally:
if con:
con.close()
if __name__ == '__main__':
make_database()
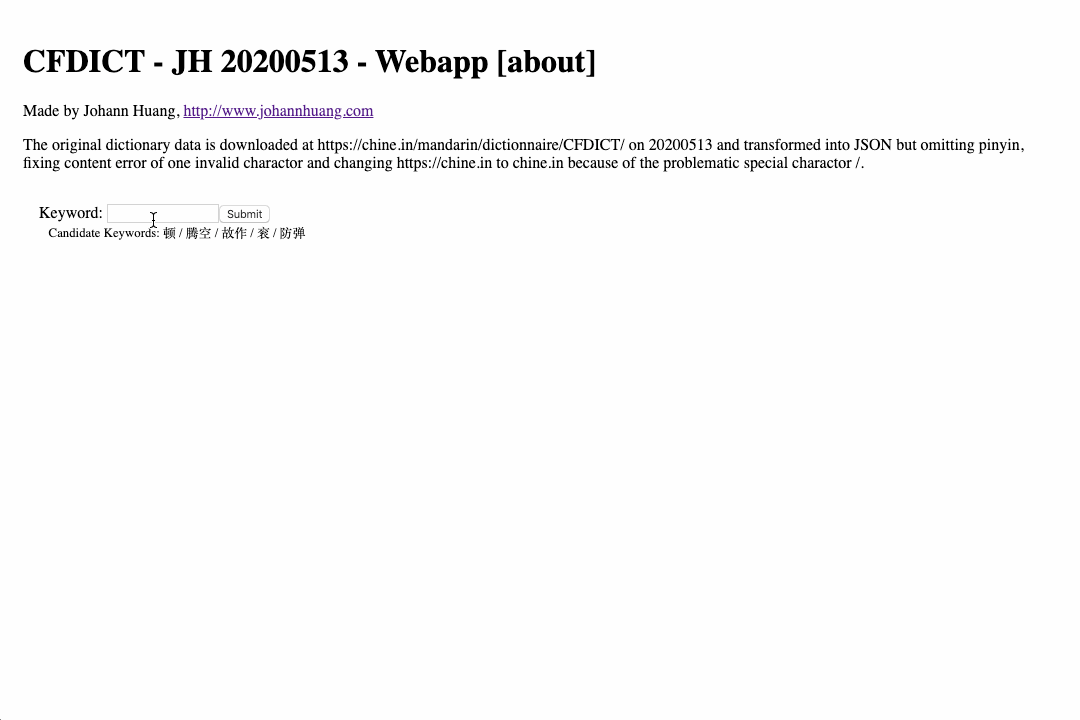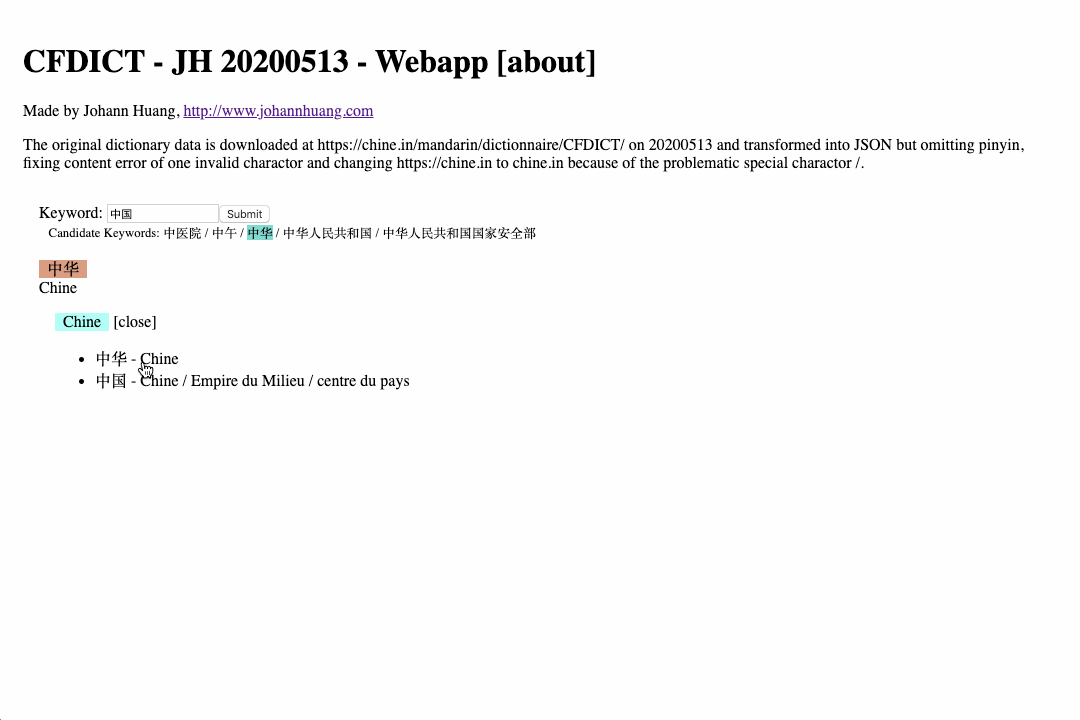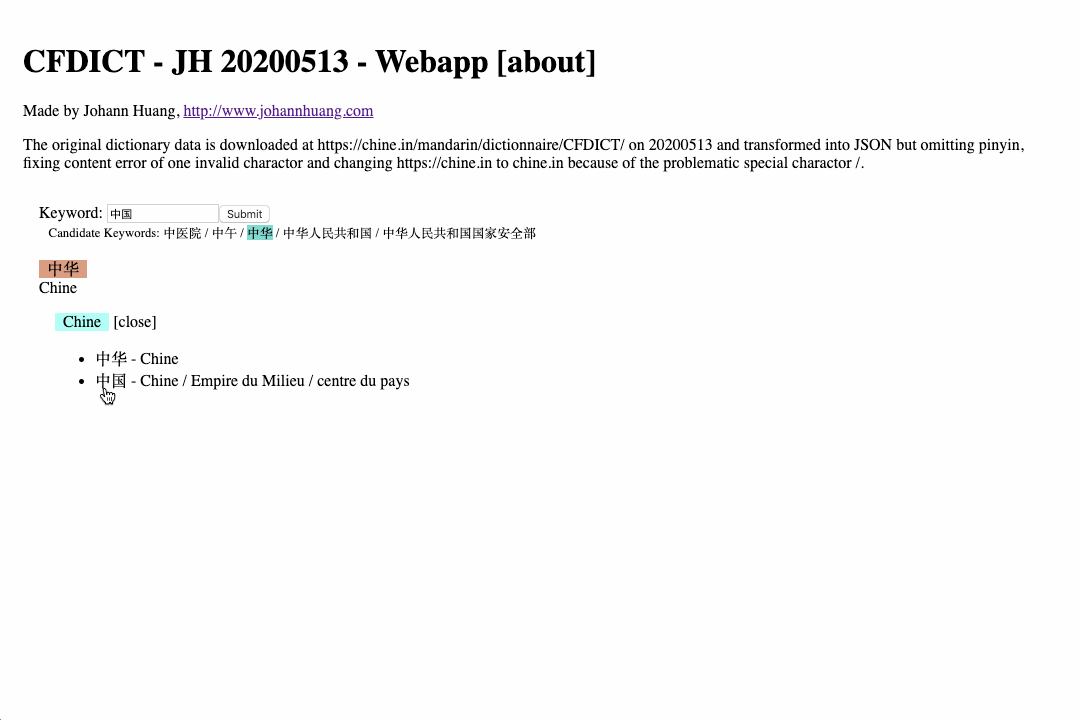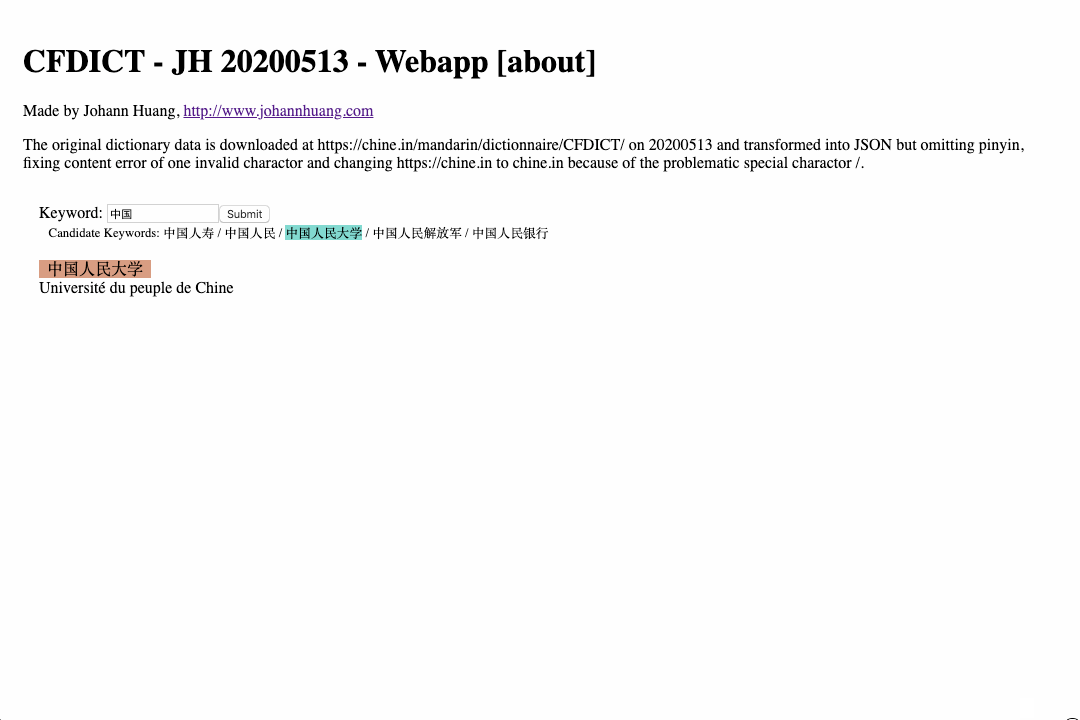
Well, last, maybe also worth mentioning, the idea of making an dictionary application for PONS Basis is also somehow related to the dictionary apps I have alread made - 3 Chinese Dictionaries. (Also be aware if you plan to open the applications, the first requests may take a while for the application to download the dictionary data in JSON format; after the first download, dictionary data will be cached in the web browser via the so called Service Worker window.navigator.serviceWorker.register('sw.js') if you open the https://www.qiasoft.de/dictionaries/ first.)
- https://www.qiasoft.de/dictionaries/
- https://www.qiasoft.de/dictionaries/cedict
- https://www.qiasoft.de/dictionaries/handedict
- https://www.qiasoft.de/dictionaries/cfdict

* cached version, generated at 2024-01-07 18:19:12 UTC.
Subscribe by RSS